Self-Consent: When Users Take Control
Self-consent empowers users, but needs verified data and consent-bound computation to eliminate friction, fraud, and misuse.

Written by
Berwin D
Insights
May 19, 2026
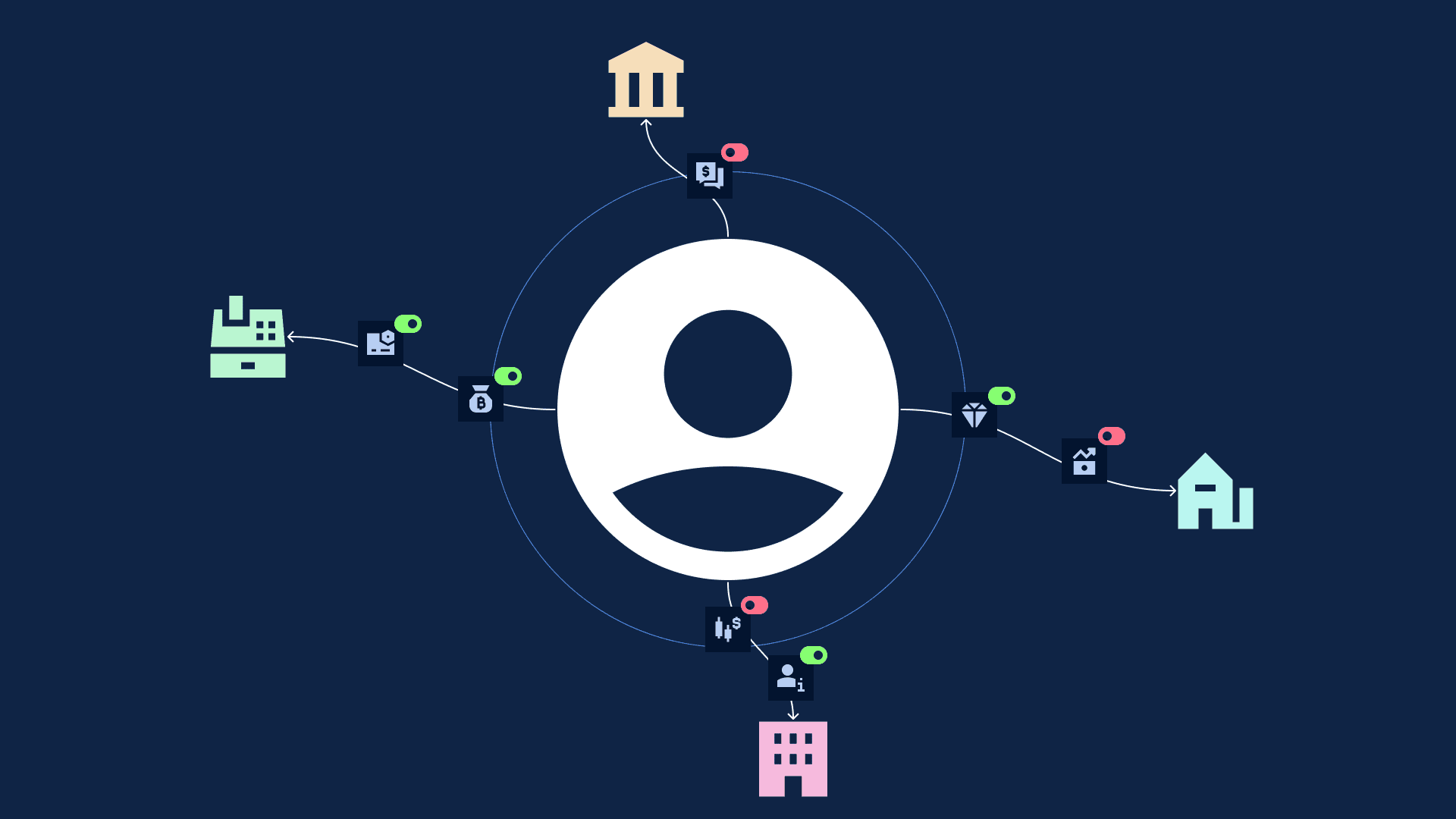
Scenario: A freelancer joins a new gig platform. To verify income, the platform requests bank statements. The freelancer logs into their bank account, navigates through multiple authentication screens, downloads PDFs for the last six months, uploads them to the platform's portal, and waits.
Three days later: Additional request for more proofs & documents.
In theory, the user owns their data. In practice, accessing it and proving its authenticity becomes a long ordeal.
In our previous blog in this series, we explored how users often misunderstand the word consent. The consent illusion gives users the impression that their data is bound to privacy automatically and is prevented from misuse. They click "I agree" and assume that the act of consenting creates a protective barrier around their information. It doesn't. Consent documents permission but doesn't enforce usage. The ideal solution requires enforcing consent in usage. When computation itself becomes consent-aware, unauthorized operations become technically impossible.

This control exists today when regulated entities request information through proper frameworks like India's Account Aggregator. But what happens when someone outside those frameworks asks for your data? A landlord verifying income. A gig platform checking payment history. An expense system validating receipts. Here, users face the friction and trust gaps we saw in the opening scenario.
User Control
Let's zoom out a bit and explore what consent is truly about: User Control.
This means the user should have the ability to control what data they share (selective inference instead of blanket sharing) and how their data is being used (misuse prevention).
The concept is straightforward. Instead of signing away broad permissions to institutions, users make granular decisions about their information. They choose what to share, decide who can see it, specify how long access lasts, and understand exactly what it will be used for. No more pages of legal text where "consent" means "we can do whatever we want with your data." Instead, users become active participants in data sharing decisions.
In theory, this solves everything. Users aren't trapped by opaque terms of service. They aren't forced to choose between sharing everything or getting no service at all. They maintain agency over their financial information, granting access selectively and revoking it when needed. It's digital sovereignty applied to personal data.
In practice, two fundamental issues arise immediately. Both stem from the infrastructure gap between what users should be able to do and what the current system actually supports.
The Issues
Issue 1: Friction for the user to get their data and share with institutions
The first barrier is operational. Getting your own financial data and sharing it with another institution takes significant time and effort.
In Canada, regulators studying data portability found that nearly 40% of users experience anxiety or outright rejection toward current self-consent flows because of security concerns, fragmented interfaces, and distrust in how data moves between systems [1]. The friction creates a lose-lose scenario: customers endure pain to access services, businesses watch potential customers disappear at each verification step.
This reveals a deeper problem. If users truly own their data, they should also be able to act as its custodian. Accessing and sharing personal financial information should not depend on navigating institution-specific workflows, downloading & uploading PDFs manually, or waiting for systems to cooperate. Control loses meaning when the user cannot reliably exercise it.
The system effectively treats portability as a feature exposed by institutions rather than a right exercised by users. The infrastructure treats data portability as an afterthought rather than a fundamental right. Banks provide download functions because they must, not because they've designed elegant data sharing workflows. And at the end of this process, users often hit the second barrier.
Issue 2: How does the data-consuming organization trust this data?
Even when users successfully navigate the friction and share their financial data, a fundamental question remains: How does the receiving organization know it's real?
Self-reported financial data faces systemic credibility issues. The numbers tell the story:

A PDF downloaded from a bank portal looks identical to a PDF edited in software. A screenshot of a transaction appears the same whether it's real or fabricated. Digital documents without cryptographic signatures carry no verifiable proof of origin or integrity.
This forces institutions to spend heavily on verification infrastructure. OCR tools to scan documents. Tampering detection software to identify alterations. Fraud detection systems to flag anomalies. Manual review teams to make judgment calls. These costs get passed back to users through higher rates, stricter requirements, and slower processing times. Everyone pays for the infrastructure gap.
The pattern is identical across use cases: manual downloads, manual redaction, uploads through various portals, manual review, and frequent rejection when verification fails. Manual verification processes average 1-2 hours per application, contributing to 10% abandonment rates across financial services [11, 12]. The process is slow, error-prone, and fundamentally insecure. Recipients can't confirm documents are authentic. Senders have no visibility into how their data will be used after sharing. Both parties operate without real infrastructure.
What We Already Have
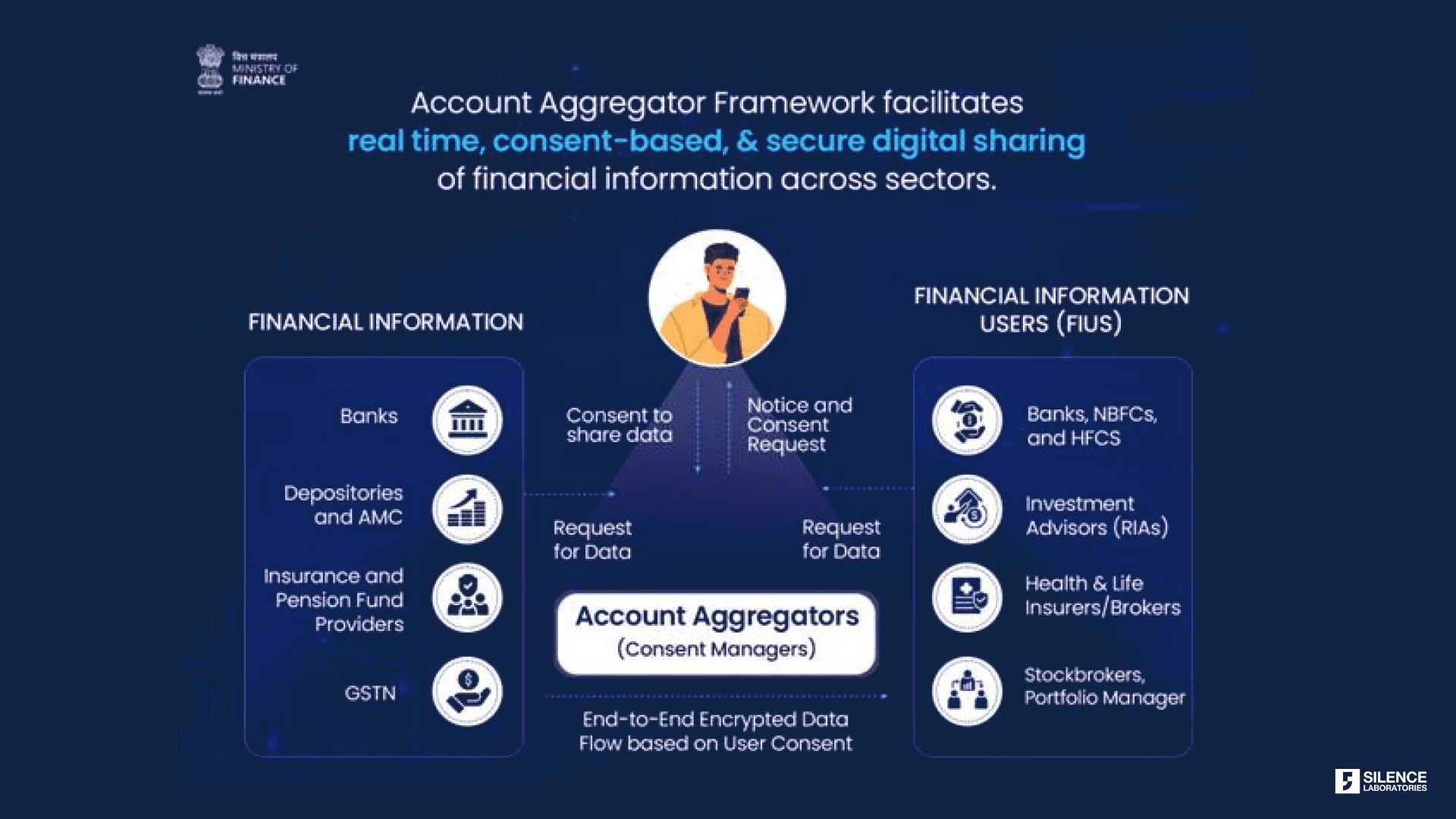
Rather than creating entirely new systems, we should expand existing frameworks that have proven they work. India's Account Aggregator system provides a working model.
India's Account Aggregator (AA) framework solves the verification and control problems elegantly for regulated entities. The growth metrics show rapid adoption [7]. As of December 2025, 126 financial institutions have gone live as both FIP (Financial Information Provider) and FIU (Financial Information User). More than 2.61 billion financial accounts are enabled to share data through the system. The scale of adoption is striking: FIUs grew from 128 to 435 in just one year. FIPs expanded from 29 to 151. Most telling, linked accounts grew 8x, from 8.92 million to 70.82 million [8]. This isn't theoretical infrastructure. It's operational, growing, and handling real financial data transfers at scale.
The AA framework provides three critical capabilities that address the issues we've discussed:

Banks verify themselves cryptographically. Users control access through explicit consent with audit trails. Recipients get authenticated data they can trust. The system handles the complexity of secure data transfer, format standardization, and consent management so that neither party has to.
Unlocking New Use Cases: Expanding User Choice
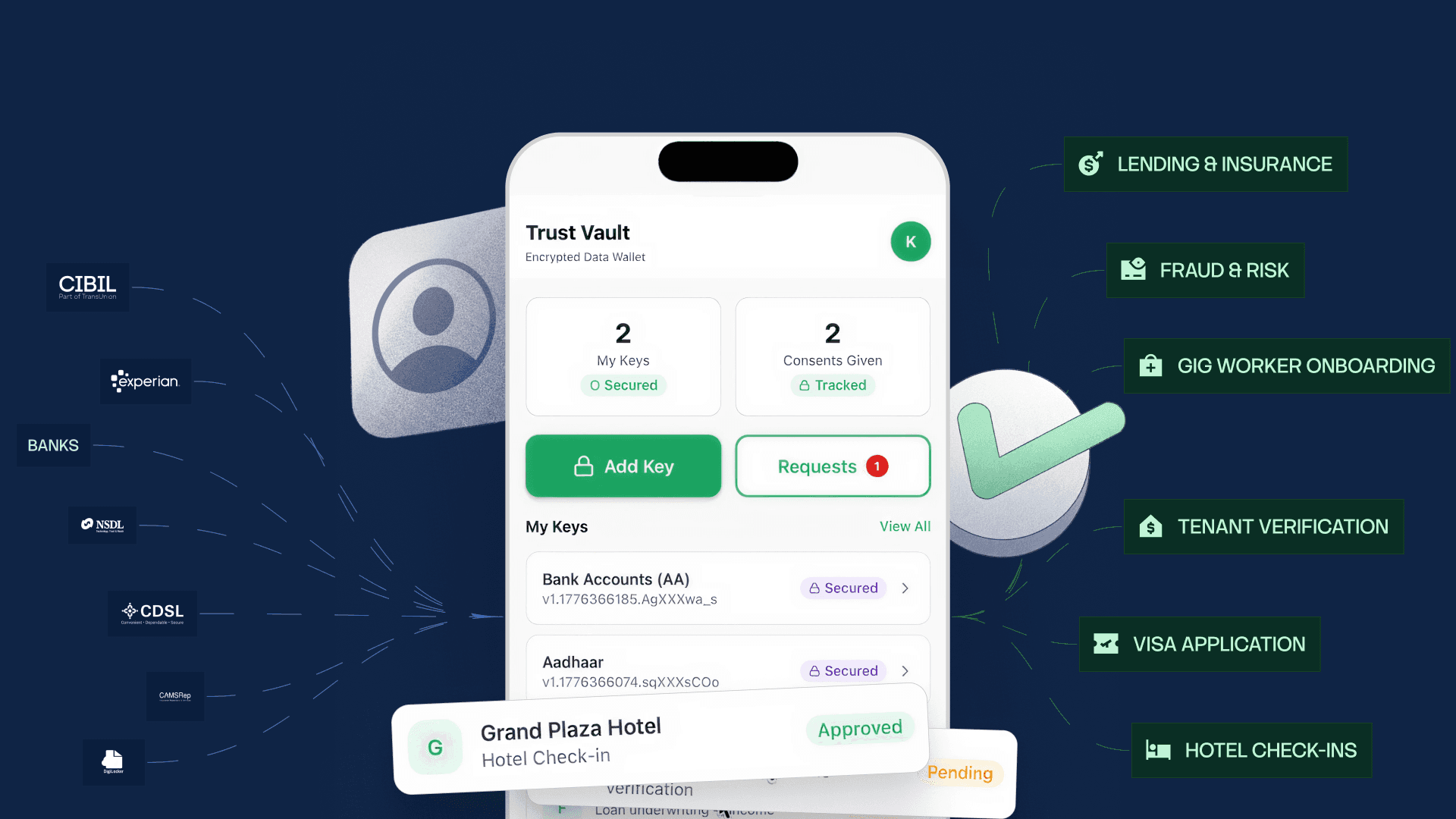
The Account Aggregator framework proves user-controlled, verified data sharing works at scale. But here's the opportunity: users should be able to share their verified financial data with anyone they choose, not just entities on a regulatory-approved list.
Consider this scenario: A platform wants to verify a freelancer's bank statement for onboarding. The platform reviews income consistency to determine which opportunities the freelancer qualifies for. This is a legitimate use case. The freelancer wants to share verified data to access better opportunities. The platform needs authentic information to make fair decisions. Both parties would benefit from secure, verified data sharing.
But today, the freelancer can't use AA for this. They're back to downloading PDFs, redacting information manually, uploading files, and hoping the platform accepts them. Not because the technology can't handle it. Not because it's unsafe. But because the platform isn't regulated by RBI, SEBI, IRDAI, or PFRDA [10].
This limitation blocks entire categories of valuable use cases where users want control:
Income verification for opportunity access: Gig platforms determining contractor qualifications, freelancers proving earnings for premium tier access, creators demonstrating revenue for brand partnerships.
Housing and financial assistance: Landlords verifying employment for rental applications, non-profits assessing eligibility for aid programs, community organizations validating need for support services.
Workplace and expense validation: Employers verifying reimbursement claims, expense management platforms authenticating receipts, HR systems confirming employment for benefits.
The question isn't whether these use cases are legitimate. It's whether users should have the infrastructure to share their own verified data for these purposes. Right now, the framework that solves verification and control exists, but users can't use it for most of the situations where they need to prove their financial information.
Expanding access would give users real choice about when and how to share their verified financial data. That's what user control actually means. And that’s where self-consent can create a path to expand AA’s trusted verification model beyond regulated FIUs, enabling user-driven data sharing across far broader real-world use cases.
This evolution mirrors the broader shift from open banking to open finance, and eventually toward open data ecosystems. Open banking focused primarily on bank account portability. Open finance expanded that scope across insurance, investments, pensions, and tax data. Open data goes one step further: enabling users to securely and selectively use verified data across a much wider range of digital interactions beyond traditional financial institutions.
The third pillar: Completing the consent-privacy framework
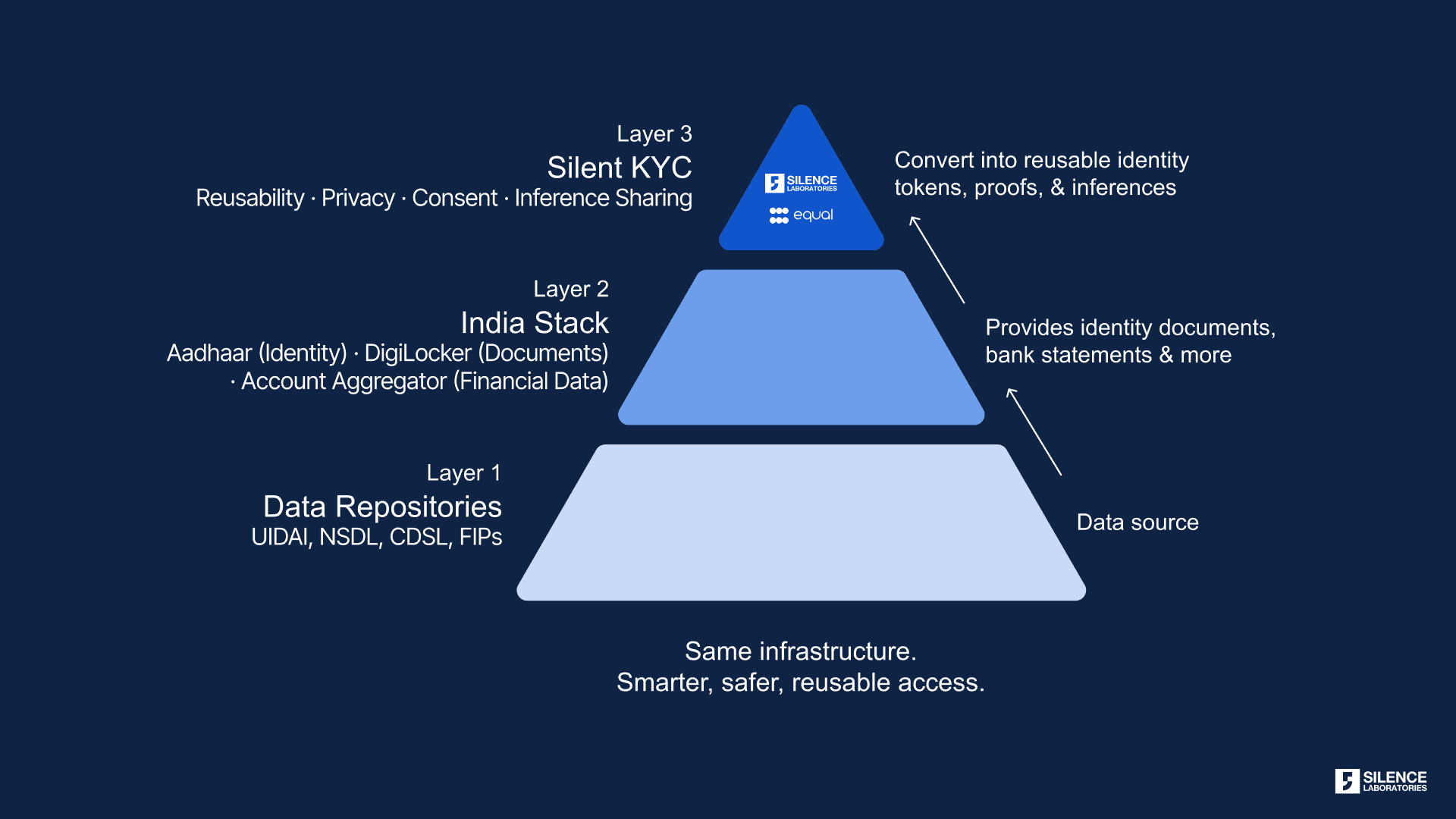
In the previous blog, we discussed two foundational pillars for privacy-preserving consent systems.
Consent should apply to inferences, not raw data. Users agree to share specific outputs such as creditworthiness, fraud signals, or income stability, rather than exposing complete financial histories. The system should move only the consented inference, never unrestricted underlying data
Computation must be bound to consent. Every operation on user data is cryptographically checked against the consent artifact before execution. The system asks: Is this computation permitted under the user's consent? If the answer is no, the computation simply cannot run. Purpose limitation becomes architectural rather than aspirational.
This blog introduces a third pillar: user custodianship of data.
Users should not merely authorize access to institutionally siloed data. They should be able to reliably access, carry, and share their own verified financial information wherever they choose.
But portability alone is insufficient. Shared data must also be provably authentic. Recipients need cryptographic guarantees that the information originated from trusted sources, has not been tampered with, and reflects the exact scope of user consent. This reduces operational friction for users while eliminating much of the verification burden for receiving organizations.
Together, these three pillars create a stronger model for digital trust & consent:
consent over inferences instead of raw data,
computation constrained by cryptographic consent enforcement,
and user-custodied, verifiable data portability
Without all three, self-consent remains incomplete.
When users share data outside regulated frameworks, usage control becomes even more critical. Financial institutions operate under continuous regulatory oversight. Entities outside those frameworks don't. This makes cryptographic enforcement of consent boundaries essential, not optional.
If data comes from the source institution with cryptographic proof of authenticity, the recipient doesn't need to guess whether it's real. This eliminates the entire category of trust problems we described earlier with falsified documents and manual verification.
This is why expanding AA access is attractive. It would immediately solve the verification problem for millions of use cases currently stuck with unverifiable PDFs. Gig platforms could trust income data. Landlords could verify employment. Expense systems could authenticate receipts.
Open data requires more than APIs. It requires user custodianship, verifiable provenance, and consent-bound computation. These are the mechanisms that allow trusted data sharing to scale beyond regulated FIUs without losing privacy, trust, or accountability.
Closing
The path forward combines three elements, each building on the others to create a system where self-consent actually works:
User-centric designs. Put users in control with explicit, granular, revocable consent. Make the interface understandable so users can make informed decisions. Provide audit trails so they can monitor usage. Design workflows that respect user agency rather than treating consent as a checkbox to bypass. This is the foundation.
Leveraging existing frameworks. Building on top of AA's capabilities. The infrastructure exists. The standards work. The adoption metrics show it scales. The question isn't whether to build new systems from scratch. It's whether to extend proven frameworks to cover the full range of legitimate use cases. This solves the verification problem and eliminates the friction of manual data transfers.
Role of privacy. Bind consent to computation so that unauthorized operations cannot run. Purpose limitation becomes technically enforced, not legally promised. This is what makes extending AA access safe. Without cryptographic enforcement of usage boundaries, expanded access creates new risks. With it, we can have both verified data and protected privacy.
Right now, we have frameworks that work for regulated entities. The infrastructure handles secure data transfer, consent management, and cryptographic verification. Extending those frameworks to give users full control over who receives their verified data would solve the friction and trust problems we've outlined. But extension without usage enforcement would be incomplete and potentially dangerous.
Self-consent should solve three problems: access, friction, and provability. Users should control their data, not institutions.
The next step is ensuring that data shared is verifiable and usage is enforceable. Verification without enforcement creates new attack surfaces. Enforcement without verification leaves the trust gap open. Both are necessary.
The framework we've outlined (user-custodied verified data, cryptographic consent enforcement, and purpose-limited computation) is currently operational.
Silent KYC, built by Silence Laboratories and Equal, demonstrates how these principles work at scale. Instead of transferring raw data, the system enables institutions to receive cryptographically verified proofs and computed inferences. Users create reusable identity and financial credentials once. Only the minimum required information is shared, strictly aligned to the purpose they approve. Raw data never leaves the source.
The architecture enforces the three pillars we discussed. For consent over inferences, the system unlocks privacy-preserving inferences such as income verification and risk signals without accessing complete financial histories. For computation bound to consent, consent is tied to computation itself. Only permitted computations can execute. It is mathematically impossible to access anything beyond consented usage. For user-custodied verifiable data, through the Equal wallet, users create credential tokens once, manage consent across institutions, delegate access, revoke at any time, and reuse verified credentials without repeating the process.
Learn more: Silent KYC: India's First User-Controlled Privacy-Preserving Identity & Data Wallet
References
[1] Environics Research, "Data portability isn't a policy detail – it's a pressure release", Open Banking Expo, February 2026
[2] Erick Watson et al., "Open Banking's Next Phase: AI, Inclusion and Collaboration", FinTech Magazine, August 2025
[3] IRS, Tax Gap Projections for Tax Year 2022, Publication 5869, October 2024
[4] Fannie Mae Economic & Strategic Research, "Leveraging Variable and Gig Income to Expand Access to Homeownership", January 2025
[5] Point Predictive, "2025 Auto Lending Fraud Trends Report", March 2025
[6] NMHC/NAA, "Pulse Survey: Analyzing the Operational Impact of Rental Application Fraud and Bad Debt", February 2024
[7] Department of Financial Services, Government of India, "Account Aggregator Framework", December 2025
[8] The Digital Fifth, "Account Aggregator", October 2025
[9] Razorpay, "What Is an Account Aggregator? RBI AA Framework Explained", December 2025
[10] Sahamati, "Account Aggregator FAQ", October 2025
11] Sikoia, "What is Document Verification and why is it important in Customer Verification?", October 2024
https://www.sikoia.com/blog/document-verification-powers-essential-customer-verification
[12] Fenergo, "Financial Crime Industry Trends 2025", October 2025
Read Part 1: [Consent Is Not Privacy: Why We Need to Rethink Data Protection]
Learn more: Open Finance Revisited: Strengthening Data Governance with Cryptographic Privacy and Auditability
SHARE


