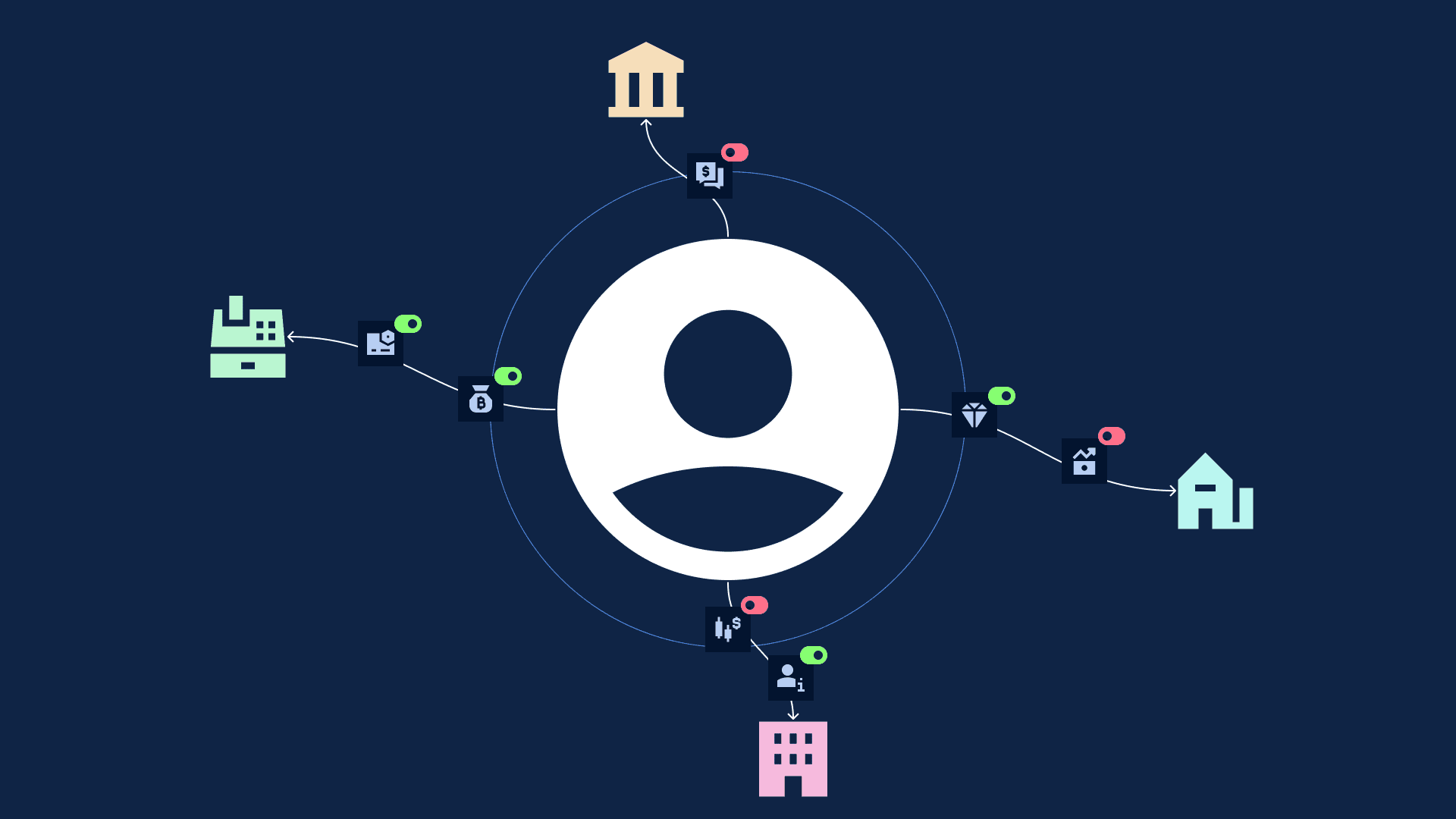
IFDT Summit 2026: Open Finance Needs Privacy by Design
Silence Laboratories at the Linux Foundation Decentralized Trust 10th Anniversary Member Summit.

Written by
Jay Prakash
Insights
Mar 15, 2026

Earlier this month, Dr. Yashvanth Kondi, Principal Scientist at Silence Laboratories, presented at the Linux Foundation Decentralized Trust Member Summit — an annual gathering of engineers, architects, and decision-makers building the decentralized financial infrastructure of the next decade.
The talk, Decentralized Open Finance via Secure Multiparty Computation, addressed what we believe is the most consequential unresolved design question in Open Finance today: not how to enable data sharing, but how to eliminate the need for raw data exposure in the first place.

The Problem Is Not Access. It Is Exposure.
Open Finance has unlocked a meaningful new category of financial services. Customer-permissioned data access, in principle, enables better underwriting, more inclusive lending, stronger fraud controls, and more precise financial products.
But the architecture underlying most Open Finance systems today rests on a fragile assumption: once consent is obtained, the data can travel across multiple intermediaries and still remain purpose-bound, safe, and properly governed. That assumption is increasingly difficult to defend technically.
The problem Yashvanth laid out is structural. Useful data under the current model becomes accessible only by being moved — copied, aggregated, processed in plaintext by parties downstream of the original custodian. This creates a direct tension between utility and privacy that consent language alone cannot resolve. Consent is a permission artifact. It is not a technical enforcement mechanism.
A survey data point from the presentation illustrates the gap: only 9% of organizations seek specific and informed consent, while 64% of users express trust in organizations that communicate clear privacy policies. The implication is significant — the current model creates a perception of control that the underlying technical architecture does not reliably deliver.
The Architectural Question That Matters
The harder question — and the one the presentation was built around — is this: can institutions compute on financial data, derive useful outputs, and serve their customers, without broadly exposing the underlying raw data? The answer, as demonstrated in the attached whitepaper and available in full here, is yes.
The mechanism is privacy-preserving computation — specifically, Secure Multiparty Computation (MPC) applied to the Open Finance data flow. Under this model, the parties involved in a financial workflow can jointly compute a required result while the underlying data remains distributed and protected. No single party, including the data fiduciary requesting the computation, ever holds the raw data in plaintext.
The design principle the presentation articulated:
The insight should move, not the raw data.

What Silent Compute Changes
This principle is operationalized through Silent Compute, Silence Laboratories' cryptographic computing engine for privacy-preserving collaboration.
The architecture presented shows how the client, the application server, the customer's bank, and external trust components — including a notary and verifier — interact through a cryptographic computing virtual machine. Consent is obtained, encrypted customer data is fetched from the bank, computation is carried out in a distributed privacy-preserving fashion, and the fiduciary receives only the inference or result it is authorized to receive. The structural comparison is direct:
Old Model | New Model |
Fiduciary receives consented customer data | Fiduciary receives consented customer inferences |
Raw data moves and is duplicated | Raw data never leaves the custodian in aggregate plaintext |
Privacy and utility in tension | Encrypted distributed processing decouples them |
Trust relies on process discipline and contracts | Trust is partially enforced through a cryptographic architecture |
Silent Compute is designed around three properties: no single point of failure for data centralization, zero plaintext exposure of data in use to processing parties, and auditability mechanisms that bind data usage to consented purpose.
India's Account Aggregator Has One Remaining Gap — and It Is the Most Important One
India's Account Aggregator framework is, by a significant margin, the most technically advanced consent-based data-sharing system deployed at population scale anywhere in the world. As of late 2024, it serves over 2.6 billion enabled financial accounts across 176 Financial Information Providers and 754 Financial Information Users, with growth that has no comparable precedent in Open Finance.
The framework's cryptographic design deserves genuine credit. The AA operator sits between the Financial Information Provider (the bank or financial institution holding customer data) and the Financial Information User (the lender or wealth manager requesting it). Data flows as an AES-256-GCM encrypted payload, keyed through an ephemeral ECDH exchange between the FIP and FIU — meaning the AA itself is architecturally prevented from reading the data it relays. This "data-blind" design is a meaningful technical advance over credential-based aggregation models, where intermediaries held bank login credentials directly.
Rahul Matthan, technology lawyer, DPI advisor to India's Ministry of Finance, and one of the most careful observers of India's data governance architecture, identified the remaining gap precisely in a November 2024 column in the Mint. His framing was surgical: the Account Aggregator system has successfully implemented most core data protection principles directly in code — but with one critical exception- Use limitation. The AA controls whether data is shared. It provides no technical mechanism to control what happens to it afterward.
This is not a regulatory oversight. It is an architectural boundary. Once the FIU decrypts the AES payload, it holds complete transaction histories, account balances, and financial records. There is no cryptographic constraint on what computations it runs, whether it retains the data beyond the consented period, or whether it combines the dataset with information from other sources to build profiles that exceed the scope of the original consent.
Matthan's column noted that a technical solution exists for this gap, pointing to approaches using data sharding and confidential multiparty computation as the architectural path to enforce use limitation in code rather than in contract.
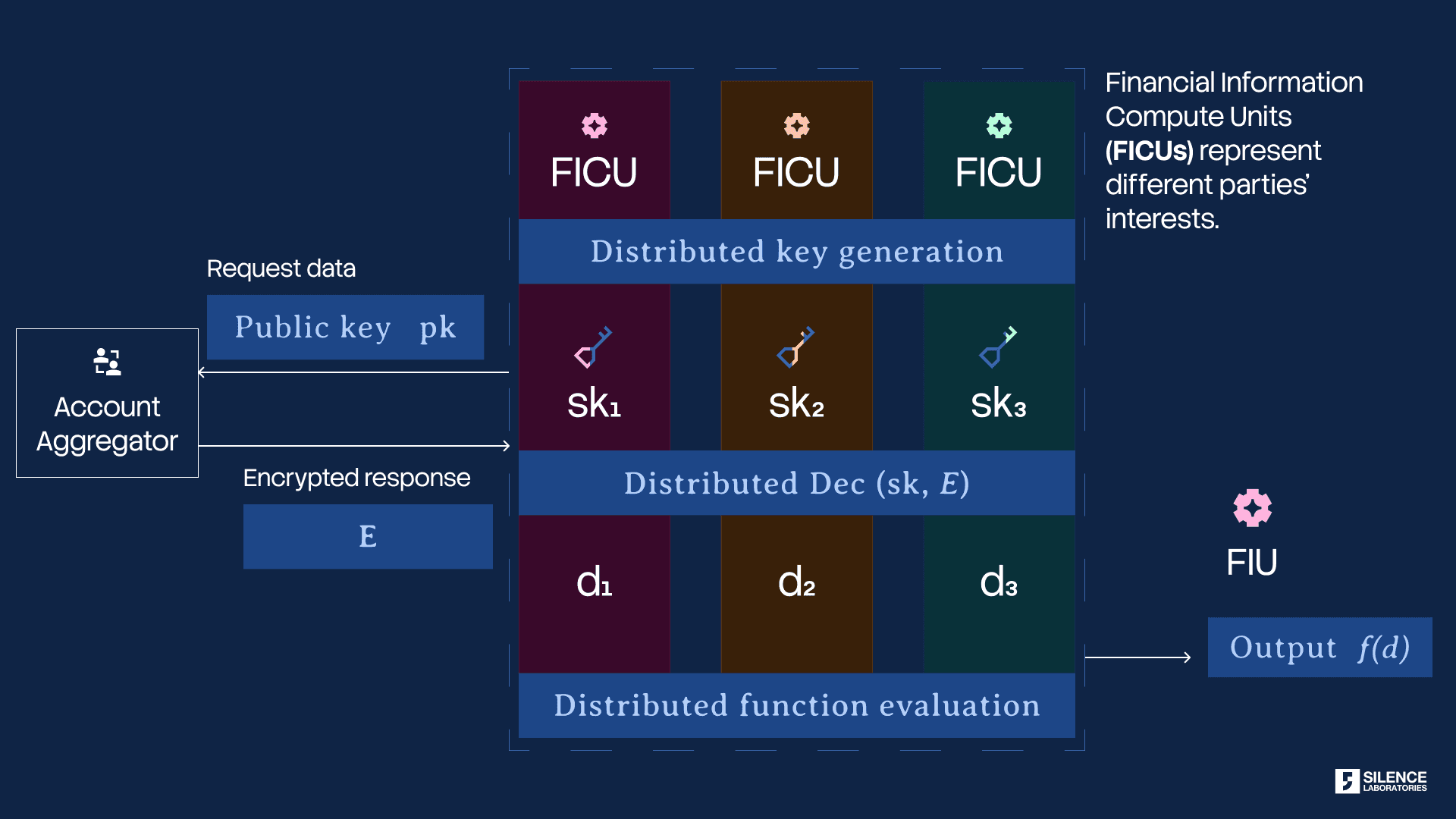
This is precisely the mechanism Silent Compute implements. Rather than delivering an encrypted payload to a single FIU endpoint — which that FIU then decrypts — the Silent Compute architecture distributes the decryption key as cryptographic shares across multiple legally isolated Financial Information Compute Units (FICUs). No single FICU can reconstruct the raw data. Instead, computation is performed across the distributed shares, and the FIU receives only the output of a pre-defined, consent-bound operation: a credit score, a risk assessment, a spending aggregate. The consent artefact is extended with signed opcode sequences that cryptographically specify which computations are permitted — turning use limitation from a compliance aspiration into a mathematical constraint.

The consequence for the AA ecosystem is categorical, not incremental. Under the current model, the trust boundary between the FIP and FIU ends at decryption. Under Silent Compute, the trust boundary extends through computation. The FIU does not merely promise not to misuse the data — it is technically incapable of accessing it in raw form. The gap Matthan identified, the one loophole in an otherwise well-designed system, closes not through stronger contracts or better audits, but through the same privacy-by-design logic that animates the AA framework itself.
We view Silent Compute not as a replacement for the Account Aggregator framework, but as its natural upgrade — completing the privacy guarantee that the AA's architects intended but that the current cryptographic architecture could not yet deliver. The AA solved the intermediary problem. Silent Compute solves the endpoint problem.
Extending Private Inference to Global Open Finance Ecosystems
The same architectural gap that Matthan identified in the Indian AA exists in every Open Finance ecosystem globally. The intermediary may differ — Plaid in the United States, Open Banking APIs in the United Kingdom, CDR in Australia — but the structural exposure is identical: the data fiduciary receives raw financial records, and use limitation depends entirely on contractual governance.
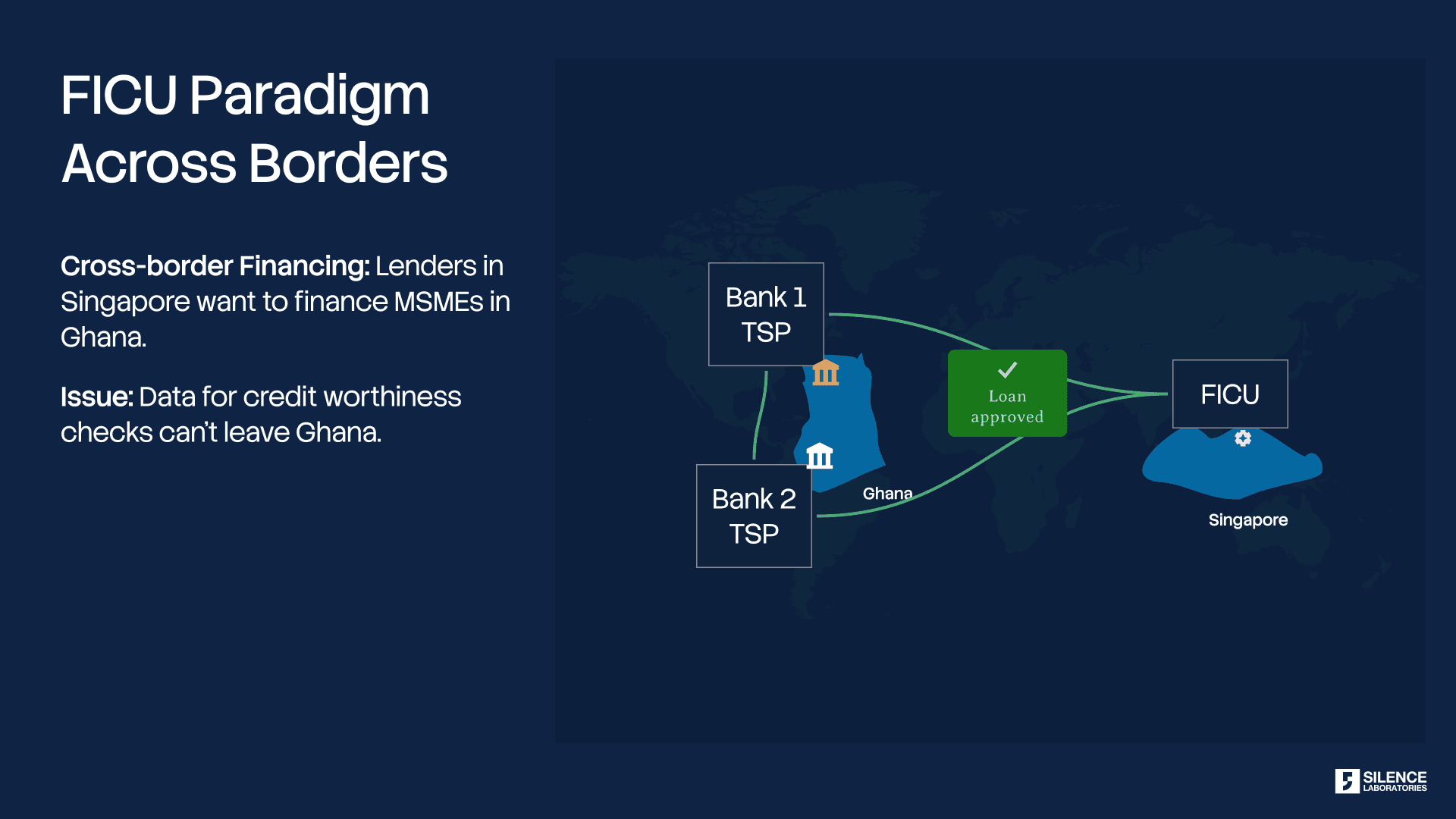
We have recently integrated private inference over Plaid, enabling Silent Compute to operate over Plaid-sourced financial data without exposing the underlying transaction records to the requesting FIU. A lender using Plaid to assess creditworthiness can now receive a computed inference — an eligibility signal, a risk score, a cashflow summary — without any party in the pipeline holding decrypted transaction-level data. The privacy guarantee is the same regardless of the Open Finance connector: the insight moves, the raw data does not.
Plaid is the first external ecosystem integration. Additional Open Finance connectors — spanning major Open Banking implementations across Europe, Southeast Asia, and Latin America — are in active development. The architecture is connector-agnostic by design: Silent Compute wraps the data retrieval and computation layer independently of the underlying consent and portability protocol, which means adding a new ecosystem is an integration exercise, not an architectural redesign.
The near-term roadmap reflects both geographic breadth and use-case depth: private credit scoring, private income verification, and private spending categorization across multiple Open Finance jurisdictions. The long-term direction is a unified privacy-preserving computation layer that any Open Finance ecosystem can adopt without modifying its existing consent infrastructure.
Why This Matters Beyond a Single Use Case
The presentation framed this not as a solution to a narrow workflow, but as a general model for how financial data collaboration should be architected.
For customers, it represents a path toward technically enforceable data boundaries — where consent approximates a cryptographic control rather than a one-time permission click. For data providers, it reduces the exposure surface and the risk burden that currently comes with participating in Open Finance ecosystems. For fiduciaries, it enables richer analytics without requiring raw data centralization. For regulators and ecosystem architects, it offers a stronger foundation for purpose-bound data use, cross-border compliance, and auditability.
The broader thesis is that as Open Banking expands into Open Finance and eventually into wider data-sharing ecosystems, the industry cannot safely scale on a model that depends on ever-wider movement of raw sensitive data. The systems that will endure are those that can prove a stronger property: that value can be extracted from data while the data itself remains protected.
What We Believe
Open Finance should not force a choice between privacy and usefulness. The next phase of financial infrastructure should be designed so that consent is tied to computation, usage remains purpose-bound and auditable, data stays distributed and protected, and institutions receive the answer they need — not the full raw dataset.
That was the core of what Yashvanth presented at the Linux Foundation Decentralized Trust summit. If you were in the room, we hope the material was useful. If you were not, the full whitepaper is available here, and we are happy to discuss the architecture in further depth.
Open Finance does not need better consent language. It needs a better compute model.

Silence Laboratories builds cryptographic infrastructure for privacy-preserving computation, threshold signatures, and key management. For inquiries, reach out at silencelaboratories.com.
SHARE