DPDP Just Moved from ‘Policy Space’ to ‘Operational Risk’

Written by
Kush Kanwar
Insights
Jan 3, 2026

Penalties up to ₹250 crore and the ability to suspend processing mean one bad architectural decision can kill a business.
The Wrong Kind of Focus
Most responses we see are cosmetic: more policies, more dashboards, more hashing.
The thinking is straightforward and myopic. Simply add controls on top of what you have. But that’s not addressing the core issue.
Raw personal data is still centralised in one place. It’s still over-collected “just in case”. And there is no way to prove what was actually done with it.
Teams focus on compliance-related audit logs, dashboards, post-breach notifications. These only matter after something goes wrong. Real prevention requires a different, proactive architecture.
What DPDP Actually Requires
According to the DPDP Act and Rules, organisations are required to:
Implement “reasonable security safeguards” like encryption, masking or virtual tokens, strict access controls, continuous logging, and meaningful retention of those logs.
Erase personal data once the purpose is over or consent is withdrawn and, for large e‑commerce, social and gaming platforms, delete inactive user data with advance notice.
Notify affected users and the Data Protection Board quickly after a breach, and make sure every processor and vendor that touches personal data can do the same.
Demonstrate auditability and accountability across all parties. When a breach happens, you must notify users and the Data Protection Board. But accountability demands you first identify which system failed, which processor was at fault, and trace the data flow across vendors
The Attribution Problem
Traditional approaches make this slow, opaque, and hard to prove. The challenge grows when data moves between organisations or across borders.
Auditability, transparency, and accountability across multiple parties and systems takes time. Attribution is nearly impossible:
When data is misused, whose logs do you trust?
What happened in the gap between systems?
How do you cryptographically verify that a processor didn’t access data beyond their stated purpose?
Traditional approaches rely on log aggregation, vendor assertions, and legal liability. All slow to reconcile. Impossible to verify independently.
Case in point: In the 2018 Marriott data breach, personal details of 339 million guests were compromised. Investigators and regulators took months to attribute responsibility between entities (Marriott and its acquired Starwood brand) due to fragmented logging and lack of transparent data flows. Accountability and notifications to affected users were delayed by technical uncertainty and unclear records, ultimately resulting in heavy regulatory scrutiny and fines. (Source)
Learning from GDPR: Retrofits Are Expensive
When privacy regulations hit other geographies, organisations learned this the hard way.
GDPR came to Europe in 2018. Organizations invested heavily in compliance preparation.
Average compliance costs for organisations ranged from $1.7 million for small firms to $70 million for larger enterprises. Yet research indicates fewer than half of organisations achieve full compliance, and average data storage and governance costs continued to rise roughly 20% post-implementation. [Source]
Why? Because most treated it as another compliance exercise. Add audit logs here. Strengthen access controls there. Tighten vendor contracts. Patch the system.

The true cost of non-compliance is much worse. According to Ponemon Institute, non-compliance costs companies 2.71 times more than maintaining compliance, factoring in business disruption, fines, and response costs. (Source)
Those organisations paid far more in the long run.
But organisations that invested in modern data governance and privacy-preserving technologies from the start saw different results. Cisco’s 2025 Privacy Benchmark found companies gained a 1.6x ROI on privacy investment, with nearly one-third seeing returns of 2x or higher. Encryption, robust access controls, and privacy by design delivered faster breach detection and reduced notification costs. (Source)
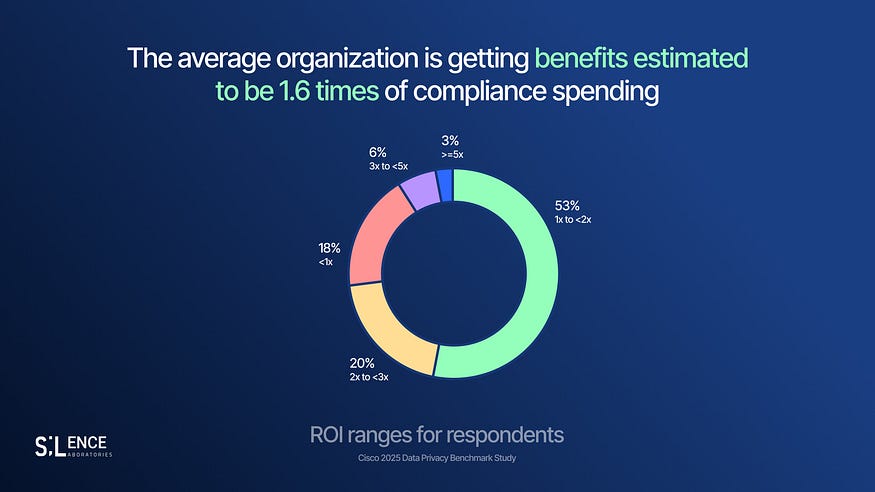
The lesson: Compliance retrofits can be expensive. Designed-in compliance is not.
DPDP is India’s moment to learn from Europe’s experience.
Why Legacy Architectures Crumble
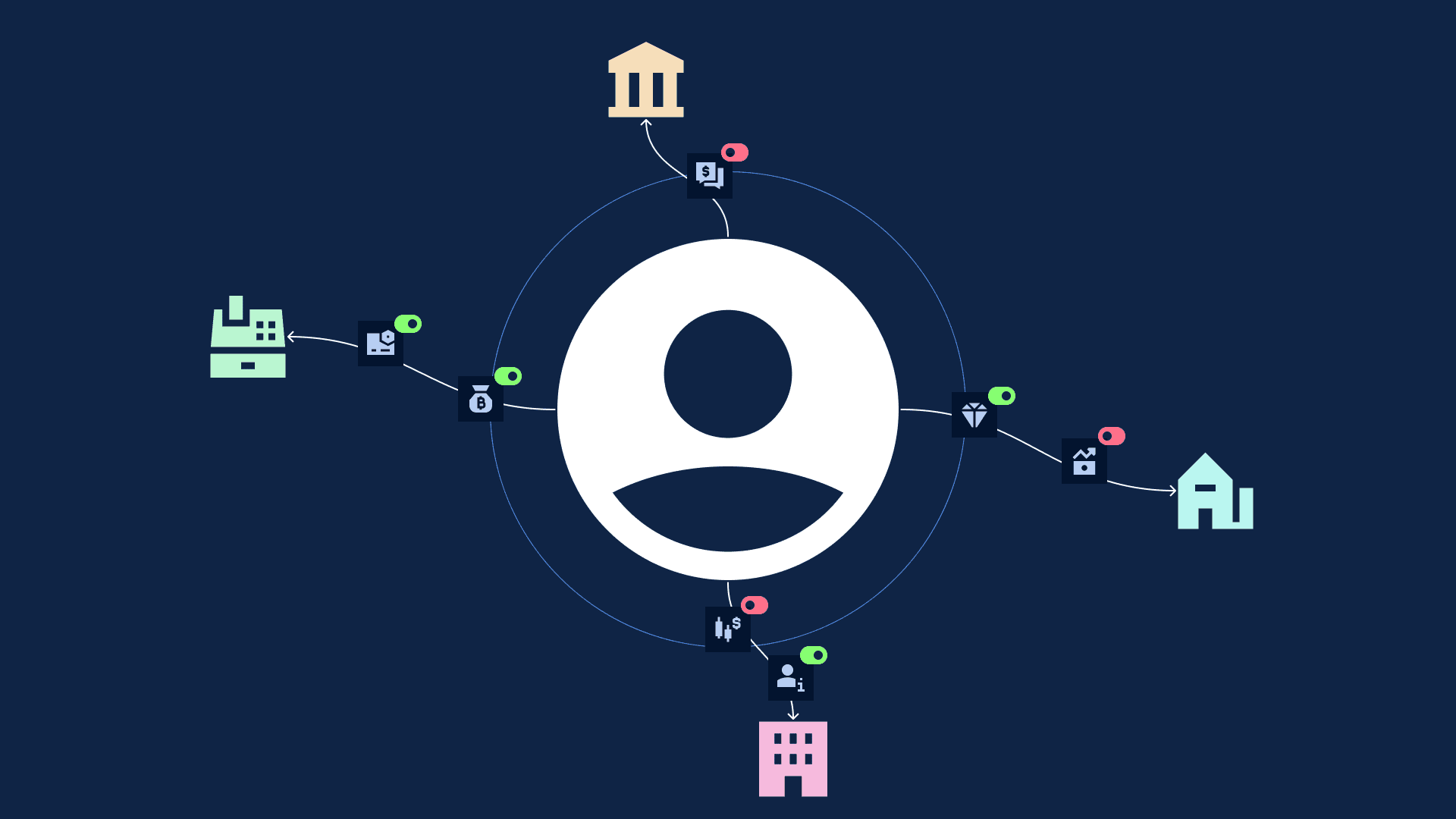
Centralising raw personal data creates a single, attractive point of failure. The underlying risk factor: moving data to a different party.
Every time personal data leaves your direct control, passed to a processor, a vendor, a third-party platform, a cross-border partner, you lose visibility and control.
You’re now dependent on contractual assurances and reactive audit trails.
If that third party misuses the data, you’re liable. If they’re breached, you still have notification obligations, reputational damage, and regulatory investigation.
It also makes limiting how data is used, and deleting it selectively, hard to enforce in code. In practice, you end up relying on logs and policies instead of cryptographic guarantees.
That is the gap we focus on.
A Different Model: Privacy-Preserving Compute
At Silence Laboratories, we bring encrypted computation (via Multi‑Party Computation and threshold cryptography) to data collaboration ecosystems.
Teams get the signals they need. Underlying personal data stays with the data owner. Never concentrated at one point. Never moved raw across parties.
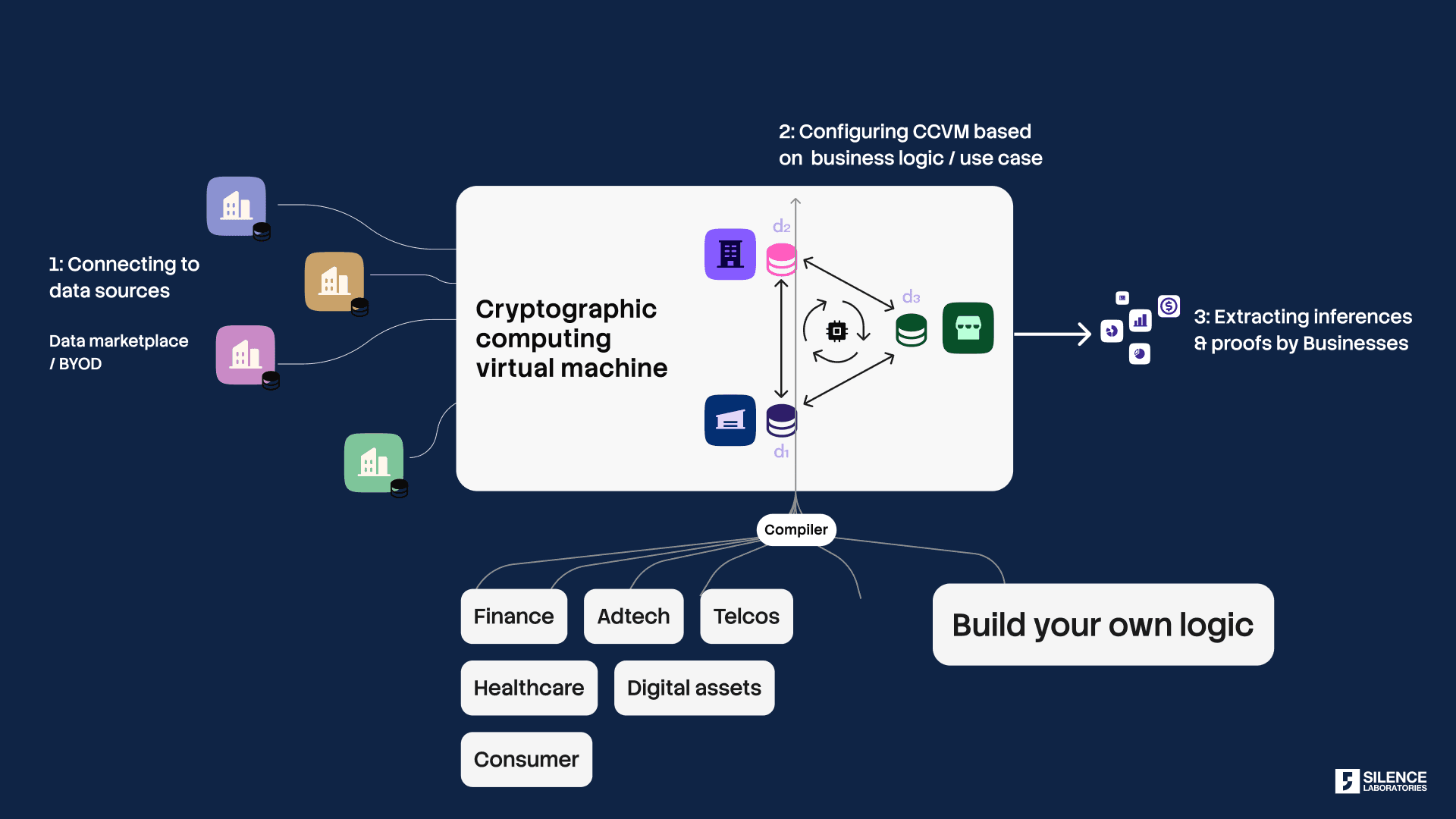
This directly addresses the problems above:
Technological enforcement of compliance. Data usage rules & consent is encoded into the computation itself. Purpose is enforced cryptographically, not just contractually.
Verifiable accountability. Cryptographic proofs replace vendor assertions. Regulators can independently verify that only agreed computations occurred, raw data was never accessed, and deletion is mathematically certain.
Reduced data movement risk. Insights cross organisational boundaries, not raw data. This structurally satisfies privacy-by-design, localisation and reduces attack surface for risk of breaches.
As an example, privacy-preserving federated analytics using Multi-Party Computation allowed health networks (including during COVID-19 data sharing in the EU) to deliver timely insights. This delivery was without ever pooling raw patient data which in turn led to faster compliance, greater collaboration, and reduced breach exposure. (Source)
Regulatory Alignment: This Isn’t Theory
Policy and regulatory bodies worldwide have increasingly advocated the adoption of Privacy Enhancing Technologies (PETs), via initiatives such as IMDA’s (Singapore) PET Sandbox, NIST’s (US) PETs Testbed and PET guides and handbooks by UK’s ICO and UN.
India can set a global benchmark by executing real-world, large-scale implementations. While the DPDP Act acts as an important catalyst to fuel adoption, proactiveness by institutions is essential, not just for compliance, but for realising the highest value from data.
Consent 🤝 Compute
What DPDP ultimately demands is not better promises, but enforceable limits.
Consent must constrain computation itself. In a compliant system, consent is not just a document, it is an executable boundary. Only what a user has explicitly consented to can be computed, and this constraint is enforced cryptographically, not through policies or post-hoc audits.
All computation runs on encrypted data, ensuring raw personal data is never exposed, aggregated, or reused beyond purpose. This is the only way to guarantee purpose limitation, provable deletion, and true prevention by making misuse mathematically impossible, not merely illegal.
This shift is already underway in India. Conversations are expanding around embedding these capabilities into systems like Account Aggregator, with Sahamati Labs working in this direction, supported by Rahul Matthan’s argument for purpose limitation enforcement through technical means.
Proof Beats Promises
In a regime where proof beats promises, “we never accessed any raw data” is a fundamentally stronger position than “we promise we used it correctly”.
If your DPDP strategy is still treating compliance as a checkbox exercise, maybe it’s time to revisit your architecture and remove the risks by design.
Whether you’re exploring private analytics for compliance, partnerships, or innovation, we’re here to help. Feel free to contact us at info@silencelaboratories.com for further details and discussion.
About Silence Laboratories
Silence Laboratories is redefining secure computation with its Cryptographic Computing Virtual Machine (CCVM), enabling enterprises to compute on encrypted data without exposing it. Combining privacy-preserving computation & consent-bound usage, we unlock new monetisation models & drive cross-industry innovation without compromising privacy.
We are a cryptography powerhouse with expertise in building Privacy Enhancing Technologies. Powered by Multi-Party Computation (MPC), our CCVM allows distributed parties to compute on private inputs & features a super-expressive virtual machine, enabling enterprises to deploy any business logic without deep cryptographic expertise. Consent is mathematically tied to every compute point, ensuring data remains protected while delivering business value. With seamless integration across finance, digital assets, healthcare, etc, we are pioneering a future where secure collaboration & innovation thrive without sacrificing privacy.
SHARE